17
Facial Actions for Biometric Applications
The face is the primary means for humans to recognize each other in everyday life, and although the human face is commonly used as a physiological biometric, very little work has been undertaken to exploit the idiosyncrasies of facial motions for computerized person identification. Previous studies such as Eigenfaces 1 and methods based on support vector machines 2 have inspired a number of two – dimensional (2D) face recognition solutions, which are now employed in various commercial and forensic applications, for example Viisage (L- 1 Identity Solutions, Littleton, MA, USA) and Cognitec (Cognitec Systems GmbH, Dresden, Germany).3
Despite such wide acceptance, the face is commonly considered to be a weak biometric because it can display many different appearances due to rigid motions (e.g., head poses) and nonrigid deformations (e.g., facial expressions), and also because of its sensitivity to illumination, aging effects, and artifices such as make- up and facial hair.4
In terms of facial analysis, three- dimensional (3D) data often simplify some processes, such as head pose and illumination problems.5 However, dealing with facial expression variability still remains an open issue. Chang and co-workers6 have suggested using expression-invariant facial regions (e.g., the region around the nose) for identity recognition; another solution is to employ statistical modelbased algorithms such as the 2D active appearance model7 (suitably extended to 3D) and the 3D morphable model,8 which can accurately interpret unseen facial poses thanks to a prior learning process.9
More recent research trends have started to consider facial expressions as an additional source of information rather than a problem to overcome. Pioneering work has reported very promising results in the contexts of speaker identification by lip-reading,10 speech/facial features,11 and lip motion. 12 However, little emphasis has been placed on examining in depth the characteristics of facial dynamics and their suitability for biometric applications, and several questions remain open:
- Are facial actions stable over long time intervals?
- How much do they vary with the subject’ s emotional and physical conditions?
- Are they sufficiently discriminative across a large population?
- Can we arbitrarily employ any facial expressions for identity recognition, or is there a hierarchy in their biometric power?
Studies have been designed to answer these questions, and investigations have been carried out to explore the uniqueness and permanence of facial actions to determine whether these can be used as a behavioral biometric.13-15 Work has been undertaken using 3D video data of participants performing a set of very short verbal and nonverbal facial actions. The data have been collected over long time intervals to assess the variability of the subjects’ emotional and physical conditions. Quantitative evaluations are performed for both the identification and the verification problems, the results indicating that emotional expressions (e.g., smiling and disgust) are not sufficiently reliable for identity recognition in real -life situations, whereas speech- related facial movements show promising potential.13-15
WHICH FACIAL ACTIONS MAKE A SUITABLE BIOMETRIC?
Is it possible that any facial actions can be considered for person recognition? In principle, this may be the case. However, choosing those which exhibit high biometric discriminative power is analogous to choosing strong computer login passwords over weak ones. It is also preferable to use very short facial actions to reduce the processing effort so that genuine users can gain access quickly to the secure services.
The majority of related work has been carried out using speech analysis,10-12 usually employing popular face databases for lip – reading and speech synthesis such as the M2VTS 16 and the XM2VTSDB, 16,17 which include audio – video data of continuously uttered digits from “0” to “9” and spoken phrases such as “Joe took father’ s green shoe bench out.” Also commonly used is the DAVID database,18 in which nine participants wearing blue lipstick utter isolated digits.
These databases have been designed for speech research purposes and are not suitable for biometrics. In fact, the use of physical markers is inconvenient for a real-life application such as biometrics, and furthermore, although long phrases are necessary for speech analysis, they require intensive processing effort, especially when 3D dynamic data are employed. Although one might consider using only short segments of the long phrases, such “cut-out” syllables are inevitably plagued by co-articulation effects, which unnecessarily complicates the problem at this early stage. For these reasons, we decided to collect a new set of very short and isolated facial actions.
With regard to speech- related facial motions, one might be tempted to see a direct link with research on speech analysis, where the distinctiveness of lip motions has been studied.19,20 However, lip-reading and biometrics are two different problems. While lip- reading aims to recognize phonemes from lip shapes (visemes) and must be speaker-independent, we seek on the contrary to recognize the visemic dissimilarities across speakers uttering the same phoneme. Another field where there has also been a great deal of interest in characterizing facial motions is orthodontics and craniofacial research. However, these studies often use a very small number of subjects (between five and 30) and examine limited speech postures,21 which is inconclusive for biometrics.
Table 17.1 English language phoneme to viseme mapping22
From P. Lucey, T. Martin and S. Sridharan, 2004, with permission from the authors.
Our objective here is to assess, first, the repeatability of viseme production over time for any speaker, and second, the distinctiveness of lip motions across speakers. To this end, we will examine a set of words chosen among the visemes of the English language as depicted in Table 17.1.
The point of articulation plays a great role in the strength of a consonant. While bilabial consonants (involving the lips; e.g., /p/, /b/, and /m/) and labiodental consonants (upper teeth and lower lip; e.g., /f/, and /v/) are informative because their visible variations can be easily captured by the camera, consonants involving internal speech organs such as the palate and the tongue (e.g., /t/, /k/, /r/, etc.) are expected to be poor because their variations are hidden.
Vowels typically form the nuclei of syllables, whereas consonants form the onsets (preceding the nuclei) and the codas (following the nuclei). A coda-less syllable of the form V, CV, or CCV – in which V stands for vowel and C for consonant – is called an open syllable, and a syllable that has a coda, such as VC, CVC, or CVCC, is called a closed syllable. The vowel of an open syllable is typically long, whereas that of a closed syllable is usually short. Two adjacent vowels in a syllable of the form CVVC usually behave as a long vowel. The r- controlled (vowel followed by “r”) and the l- e- controlled (consonant-l- e at end of syllable) are neither long nor short, but allow trailing, as in a long vowel.23
Our comparative evaluation has been performed on different types of syllable, using the following words: “puppy” (CVC/CV, short vowel/long vowel), “baby” (CV/CV, long vowel/long vowel), “mushroom” (CVCC/CVVC, short vowel/long vowel), “password” (CVCC/CVC, irregular case: long vowel/r controlled vowel), “ice cream” (VCV/CCVVC, long vowel/long vowel), “bubble” (CVC/CV, short vowel/l -e-controlled), “cardiff” (CVC/CVC, r-controlled vowel/short vowel), “bob” (CVC, short vowel), and “rope” (CVC, irregular case: long vowel).
Unlike visual speech, which involves mainly lip motions, emotional expressions also involve movements of the forehead, the eyebrows, the eyes, the nose, etc. Thus, in order to accurately capture the idiosyncrasies of a person’ s facial dynamics, the entire face needs to be analyzed. However, such a holistic approach may be computationally prohibitive. Therefore, it is useful to determine which facial regions are the most important to convey identity, so that we can analyze only the most informative part of the face. This question has already been investigated in perceptual studies, but these works were carried out on 2D still images rather than on 3D dynamic data, and there have been so far no convergent conclusions. Whereas Brunelli and Poggio24 suggested that the mouth is the most discriminative facial feature across individuals, more recent studies indicate that it is rather the eyebrows, followed by the eyes, the mouth, and the nose.25
We have examined a set of facial actions involving facial muscles. We have studied the basic emotions (e.g., smiling and disgust) along with a number of facial action units (AU) based on the Facial Action Coding System (FACS),13 for example brow raiser (AU1 + 2), brow lowerer (AU4), upper lid raiser (AU5), nose wrinkler (AU9), and lip corner puller (AU12). Interestingly, research in orthodontics and craniofacial research has found evidence that facial actions involving maximal muscle stretches are more reproducible than moderate expressions. 21 Therefore, we have focused on facial expressions of maximum intensity only.
To collect data on facial actions for our research, two 3D video cameras operating at 48 frames per second are employed (Figure 17.1). Although the cameras have been purchased from the same provider (3dMDface Dynamic System; 3dMD, Atlanta, GA, USA), they are of different generations, hence the 3D mesh densities and the texture qualities they produce are noticeably different. The recording sessions are carried out in two laboratories with different ambient conditions (daylight or dark room), and there is no strict control of the head position; small head movements are allowed as long as we ensure an ear – to – ear coverage of the face. No physical markers are used. Such settings resemble a real-life scenario where faces are also expected to be collected from different data capture devices in different recording conditions. In this way, we can evaluate how well our recognition algorithm performs on data of variable quality that have been collected in moderately constrained environments (Figure 17.2).
Figure 17.1 The 3dMDface Dynamic System (3dMD, Atlanta, Georgia, USA).

Figure 17.2 In different recording sessions with different people, participants are required to speak in a normal and relaxed way.
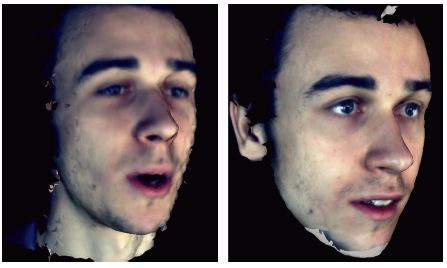
The subjects were staff and students recruited within Cardiff University, UK. All were naï ve users who have not been trained beforehand; in particular, none was familiar with the FACS. 26 The participants were asked to perform a number of basic emotions/expressions (e.g., smile, disgust) and a small set of AUs as described, targeting a maximal muscle stretch; on the other hand, they were also required to utter a set of isolated words, speaking in a normal and relaxed way.
The recording sessions were scheduled over long time intervals (ranging from a few weeks to over 2 years) to assess the variability of the subjects’ emotional and physical conditions. We have been able to collect data from 94 participants (61 males and 33 females, 70 of whom were natural English speakers). The word “puppy” was studied in some subjects over 2 years. Fifteen participants were used to study other utterances (e.g., “password,” “mushroom,” etc.), and the repetitions were recorded over a period of 1 month maximum. The smile dynamic has been studied in 50 subjects, and smaller tests were conducted on FACS AUs.
Many techniques have been proposed for extracting facial dynamic features, which do not require the use of physical markers. For example, the work of Pamudurthy and co- workers aimed to track the motion of skin pores,27 whereas the work of Faraj and Bigun12 used the velocity of lip motions for speaker recognition. These methods are interesting and novel; nevertheless, they still require more research. In this study, we adopt another feature- extraction approach relying on the well- established model- based algorithms used in static face recognition, for example the active appearance model7 and the morphable model.8,13-15 The data pre- processing and feature extraction steps are briefly outlined below.
Face normalization
One nontrivial preliminary task in face recognition is to normalize the scans so that they can be compared in the same coordinate frame (i.e., with a similar head pose and size). The normalization is achieved using a nose- matching technique proposed b/>
Stay updated, free dental videos. Join our Telegram channel
VIDEdental - Online dental courses


