The introduction of 3-dimensional (3D) volumetric technology and the massive amount of information that can be obtained from it compels the introduction of new methods and new technology for orthodontic diagnosis and treatment planning. In this article, methods and tools are introduced for managing 3D images of orthodontic patients. These tools enable the creation of a virtual model and automatic localization of landmarks on the 3D volumes. They allow the user to isolate a targeted region such as the mandible or the maxilla, manipulate it, and then reattach it to the 3D model. For an integrated protocol, these procedures are followed by registration of the 3D volumes to evaluate the amount of work accomplished. This paves the way for the prospective treatment analysis approach, analysis of the end result, subtraction analysis, and treatment analysis.
With the introduction of 3-dimensional (3D) technology, producing a patient’s 3D virtual image became an achievable reality. However, to make the 3D volume versatile and usable, we need diagnostic tools that enable us to detect defective skeletal and dental areas. We also need tools that allow us to detach, manipulate, and adjust various parts of the dentofacial skeleton, and then reattach them. In this article, a technique for these tasks is introduced.
Material and methods
Acquisition of the patient’s 3D virtual model is the foundation. Computed tomography (CT) slices of the patient’s head (soft and hard tissues) are obtained in digital imaging and communication in medicine (DICOM) format. These cuts are then compiled to create a 3D model. By using a ray-casting volume-rendering technique, a digital 3D replica is built. This volume-rendering formula provides more information of the anatomic details of the dentofacial skeleton for better visualization of the 3D model of the head ( Fig 1 ). Surface-rendering formulas are available for additional manipulation. For automatic separation of the mandible from the skull, a consistent interocclusal clearance is essential throughout the arch length, to facilitate the training of the artificial intelligence. Hence, an important prerequisite of the imaging procedure is to acquire the CT images with the teeth in disclusion. This dental separation should be within the interocclusal freeway space, where the condyles experience pure rotation around the condylar hinge axis. In such position the condyles are functionally centered in the glenoid fossa (centric relation), hence, the facial pattern of the patient is preserved, and a reproducible posture is obtained, in addition to elimination of functional occlusal shifts due to premature occlusal interferences. Subsequent localization of the condylar hinge axis allows for mandibular rerotation into maximum interdigitation when necessary.
On the contrary, capturing the CT images without interocclusal separation produces slides with blended maxillary and mandibular teeth. This results in loss of anatomic details and in turn, jeopardizes the accuracy of the dental measurements. Through occlusal separation, occlusal details are visible, and the maxillary and mandibular separation is technically precise.
For occlusal separation, the patient wears a custom-made mandibular splint during radiographic image acquisition. The splint is fabricated with a vacuum-pressing machine. A 2-mm hard plastic sheet is custom made on the patient’s mandibular model. The splint is then tried in the patient’s mouth. The patient is instructed to occlude on an articulating paper to mark the points of initial contact. Marks on the splint are accurately and mildly ground to guide the maxillary teeth into their shallow grooves and avoid eccentric occlusions. Such manipulations of the splint will reduce its thickness to 1 mm. Hence, a minimal posterior dental separation is obtainable with the mandible maintained in centric relation.
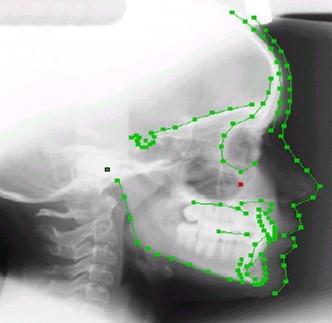
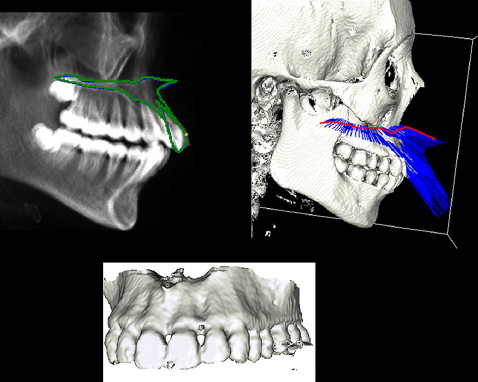
The algorithm used for automatic mandibular separation stems from a previous approach for fully automatic identification of 2-dimensional (2D) cephalometric landmarks. This approach was developed by unifying an active appearance model and simulated annealing for automatic cephalometric landmarks localization on 2D lateral radiographic images ( Fig 2 ). The results showed that the active appearance model followed by simulated annealing can give more accurate results than an active shape model. This technique was extended to obtain landmarks for both lateral and frontal images.
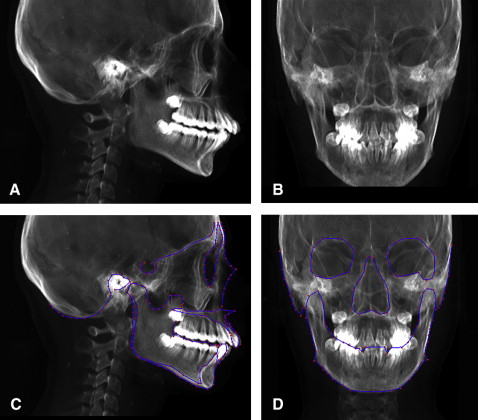
Our approach depends on determining the landmarks from the 2D model and then processing them to generate their corresponding landmarks on the 3D model. This procedure starts by building digital reconstructed radiography from the patient’s 3D images. This means generating the lateral and posteroanterior cephalograms from the 3D model of the patient’s head ( Fig 3 , A and B ). These cephalograms are fed into the computer for automatic 2D landmark identification with the previously mentioned technique ( Fig 3 , C and D ). Identical automatically detected landmarks on the lateral and frontal cephalograms are processed to generate their equivalent lines on the 3D model of the patient’s head ( Fig 4 ). Because point landmarks on the 2D images are represented as lines on the 3D model, the generated lines will be perpendicular on the y-z and x-z planes, respectively. Hence, the intersection of the two generated lines is a point on the 3D image. Thus each landmark generated from equivalent frontal and lateral landmarks, is represented as a corresponding landmark on the 3D skull model ( Fig 5 ).
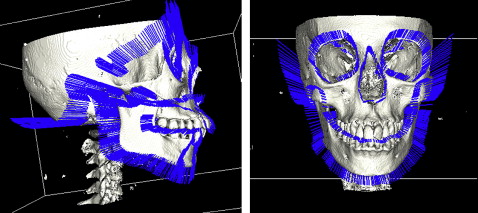
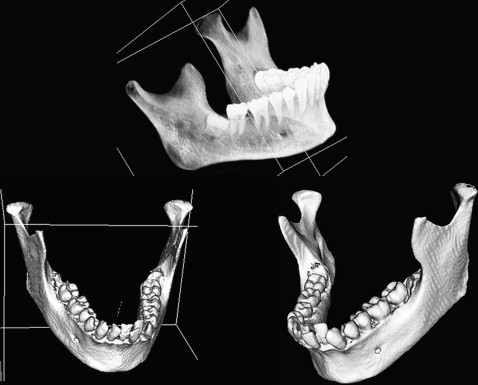
Using this technique, the mandibular landmarks from 3D cephalometry were automatically selected. This represents the initial data to accomplish the mandibular separation. In addition, a faster operation is guaranteed by automatically determining an imaginary boundary box for the mandible from the 3D cephalometric landmarks. Hence, a fully automated approach is developed for mandibular separation ( Fig 6 ).
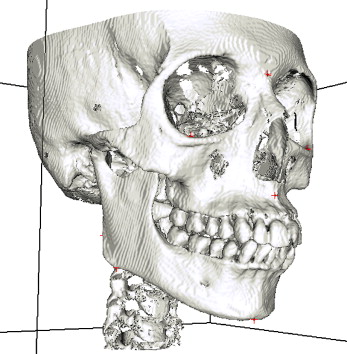
Likewise, the fully automatic parting of the maxilla with its attached dental structures begins with the training of the artificial intelligence. In this approach, the landmarks allocated on the 3D image with the boundary points of the maxilla are used to separate the maxilla in the 3D model. The boundary points of the maxilla are learned from the lateral cephalometric image generated from the 3D image. The generated maxillary contour fed into the computer makes it possible to trace the maxillary border with subsequent maxillary separation ( Fig 7 ).
Both techniques used for automatic separation of the mandible and the maxilla can be used for symmetric and asymmetric patients, since the technique is boundary oriented.
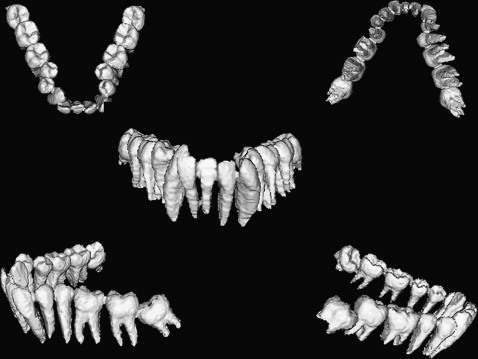
Separation of the dentition from the adjoined skeletal base facilitates the dental manipulation. The difficulty of extracting the teeth from CT images is due to the similarity in intensity with the surrounding bone. The technique depends on the fact that the dental enamel can be allocated easily because of its maximum intensity in the image and is automatically extracted by the threshold segmentation technique. The crowns are used to complete the segmentation of the roots by checking the connectivity for each pixel in the root data with the crown pixel in the tooth data. The segmentation technique depends on manually assigning a centroid for each tooth. Using K-means clustering (a method for clustering objects into arbitrary number of classes [K], where classes are defined by their means) and the connected component algorithms, tooth boundaries are identified. By using region-growing techniques, the whole dentition can be separated from the rest of the skeletal base ( Fig 8 ). Subsequent separation of individual teeth and the ability to color each tooth separately facilitates implementation and simulation of the various orthodontic applications ( Fig 9 ). Further maneuvering of the dental units separately, simulation of the extraction procedure, and virtual aligning of the teeth are the beginning of the virtual digital computer-based 3D diagnostic setup ( Fig 10 ).