Introduction
Esthetic considerations play an increasingly important role in patient care, and clinicians need a methodology that includes imaging techniques to capture the dynamic nature of the smile. Photographs of the posed smile are routinely used to guide diagnosis and treatment, but there is no standardized and validated method for recording the dynamic smile. The purposes of this study were to (1) determine whether a posed smile is reproducible, (2) compare visual and verbal cues in eliciting a smile, and (3) compare the diagnostic value of videography and photography in evaluating a patient’s smile.
Methods
The smiles of 22 subjects were simultaneously photographed and videotaped on 2 separate occasions. For objective comparisons, measurements of the smile were obtained from 8 × 10 color still photographs and selected digitized video images. A panel consisting of a layperson, an oral surgeon, an orthodontist, and a prosthodontist subjectively assessed the reproducibility of the smile, posed vs spontaneous smiles, and the diagnostic value of video vs still images.
Results
Objective measurements showed that the posed smile can be reliably reproduced, whether captured by videography or still photography. However, subjectively, the panel members detected differences between the posed smiles taken on different days 80% of the time. The clinician panel members expressed a strong preference for videography over photography and for the spontaneous over the posed smiles.
Conclusions
This study emphasizes the need to continue to investigate and standardize the methods of eliciting and recording a smile of diagnostic quality.
As part of a facial esthetic evaluation, the clinician studies lip function and posture. During this evaluation, the patient is often asked to smile, and a split-second image of that dynamic action is captured on a still photograph. This photograph, used as part of the diagnostic process to determine a course of treatment, remains as a permanent record in the patient’s chart. If we want to depend on a still photograph to reflect the esthetics of a patient’s smile, it is necessary to capture a true representation of that smile. For instance, if the photo was taken a few seconds earlier or later, would it show the same smile? If a different directive was used to elicit a smile, would it trigger the same response? Would videography rather than photography provide a more effective diagnostic impression?
Previous studies have qualitatively and quantitatively addressed the movement of a smile. Studies in the psychology literature have found that people are better able to detect posed emotion from motion photography than from still photography. Nonetheless, the dental literature is surprisingly lacking in its discussion of the dynamic nature of the smile as it relates to the methods used to elicit, record, and reproduce it and how it reflects our patients’ esthetics.
The aims of this study were to investigate the potential variability in current methods of evoking a smile for analysis and to evaluate the relative diagnostic value of videography vs photography in capturing a dynamic event. It is necessary to be critical of the tools used to determine a treatment plan and to make great efforts to standardize them.
Material and methods
Twenty-two subjects volunteered to participate in the principal portion of this study. They were students, faculty, and staff from Manhattan College, Bronx, New York. The only exclusionary criteria were visible developmental or traumatic abnormalities of the face or facial musculature, and missing anterior teeth.
The subjects were simultaneously photographed and videotaped on 2 days. All participants signed informed consents but were not told that we were looking for possible reproducibility of the smile or any other information that would bias their responses.
The position of each subject’s head was standardized by a head holder designed specifically for this study. The holder positioned the head with a 3-point contact in both the vertical and horizontal dimensions: 2 ear rods were placed in the external auditory meati and a pad on the forehead. A series of black rectangular markers, 1 inch long and 1 inch apart, were placed on the head holder and captured in the photographs to correct for any alteration in magnification from image to image. The head holder was fastened to a stand, which held it in a constant position vertically and horizontally. The height of the chair was adjusted to accommodate for the subjects’ variations in height. Measurements of the horizontal and vertical positions of the forehead pad were taken with a millimeter ruler at the first session, and the head holder was reset to these same measurements for each subsequent session.
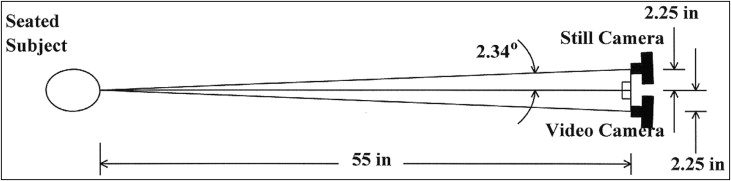
Two cameras were arranged so that each subject could be photographed and videotaped simultaneously. For the 2 cameras to be used simultaneously, thus capturing the same smile, it was necessary to set up isosceles triangles between the subject and each camera mounted on tripods ( Fig 1 ). The centers of the 2 camera lenses were placed 4 ft 7 in from the anterior portion of the head holder and 2.25 in from the center (a line extended from the midsagittal plane of the subject setup). This made an angle of 2.34° from the midsagittal plane of the subject to the center of each camera lens, creating a negligible distortion as determined by an optical error analysis.
For the still photography, at each session, 2 photographs of the subject were taken. The first photograph was prompted by a verbal directive and the second by a visual directive. The verbal directive was “give me a nice, big smile, one that shows your teeth.” A poster board with color photographs of 6 people smiling broadly was used for the visual directive, and the subjects were told to “smile like the people in the photographs.” The verbal directive was uniformly given first to prevent the subjects from relying on the memory of the visual image when presented with the verbal command.
The frontal photographs were taken by the same operator (J.F.W.) using a Pentax K-1000 camera (Asahi Optical, Tokyo, Japan) with a 90-mm F/2.8 macro lens (Sigma, Tokyo, Japan) mounted on a tripod, 35-mm Kodachrome ISO 64 slide film (Eastman Kodak, Rochester, NY), and a standardized camera-to-source distance of 4 ft 7 in. All 88 slides, which resulted from the 22 subjects being photographed 2 times at the 2 separate sessions each, were then converted into 8 × 10 color copies via a Kodak 1550 Plus printer (Eastman Kodak) for analytical purposes. The still images shown to the panel were cropped to include only a standardized border beyond the vermilion of the lips.
For the videography, a Panasonic Palmcorder VHS-C video camera (Matsushita Electric Corporation of America, Osaka, Japan) mounted on a tripod was manually focused to show a close-up, full-face view of each subject. VHS-C film was used. The object-to-source distance was also 4 ft 7 in. The video camera was turned on before the verbal directive and remained on throughout the entire session.
Randomly, 1 image from the video footage (either the verbal or the visual smile from either day 1 or 2) was selected for each subject to use for comparison with the still images. The apex or height of each of the 22 randomly selected smiles was determined by agreement of 2 evaluators (J.F.W. and G.J.C.). In the case of a disagreement, a third evaluator was used. The apex of a smile was defined as the frame in which the smile was the largest. To measure the video images, the apices of the smiles were converted into 35-mm slides and then into 8 × 10 color copies, using the Kodak 1550 Plus. The Media Suite Pro video-editing program (Avid Technology, Tewksbury, Mass) was used to create a videotape of each subject’s smile to be viewed by the panel.
In 13 of the 22 subjects, the video camera was able to capture an unsolicited spontaneous smile. The smiles were deemed spontaneous by 2 evaluators viewing the unedited video footage using the following criteria: (1) there was no cue by the photographer to smile before the smile and (2) the subject appeared relaxed and was conversing with the photographer. Two examiners, with a third examiner consulted when there was a difference of opinion between the 2 original evaluators, also selected the apices of these spontaneous smiles. The apices of these smiles were then converted into 8 × 10 color copies with the Kodak 1550 Plus.
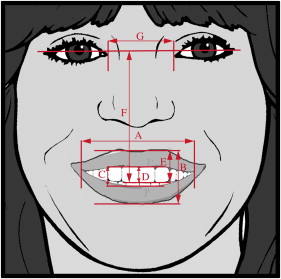
For an objective assessment and comparison of the still and video-derived images described above, measurements were taken twice by the same operator (J.F.W.) with a vernier caliper to the nearest 0.1 mm, then averaged ( Fig 2 ).
A panel of 4 people was selected to provide subjective assessments of the smiles. The panel included a prosthodontist (rater 1), an orthodontist (rater 2), a layperson (rater 3), and an oral surgeon (rater 4).
The panel portion of this study was divided into 4 parts. Part 1 addressed the issue of reproducibility of the smiles using still photography. Part 2 compared the diagnostic value of the 2 media: videography and still photography. With video technology, parts 3 and 4 provided comparisons of spontaneous and posed smiles. All 4 panel members were shown parts 1, 3, and 4, whereas part 2 was shown to the professional members of the panel only because it required a comparison of the diagnostic value of video vs still images.
The following is a description of the 4 parts shown to the panel.
- 1.
Still photographs day 1 vs day 2. By random selection, either the verbal or the visual set of still photographs was selected for each subject to be shown to the panel. The randomly selected smile photos were cropped to display only a standardized border just beyond the vermilion border of the lips so as not to distract the panel with other facial features and extraneous details such as hairstyle and makeup.
Each panel member independently was asked to determine whether he or she thought that the 2 smiles were the same. Twenty-six sets of smiles were projected next to each other on a screen. To ascertain the validity of each panel member’s responses, 4 of the 26 sets of photographs reviewed were actually duplicates, with the same pictures shown side by side.
- 2.
Still photography vs videography. The 22 randomly selected smiles were then shown to the 3 professional members of the panel in both the video and still formats. This provided a subjective comparison of the clinical value of the still and video smiles. The panel members were asked to fill out a form that asked 2 questions: (1) which is more useful diagnostically, the still photo, the video footage, or no preference? and (2) do you have any comments regarding preference?
- 3.
Posed vs spontaneous smiles (uncropped). The 4 panelists were shown the series of full-faced posed smiles along with their spontaneous counterpart, both obtained from the video footage. They were asked to select the most diagnostically useful image. “Diagnostically useful” was defined as the smile that appeared to be the most natural, the one that seemed to best represent the subject’s unsolicited smile. The layperson was told to select the smile that appeared most natural.
- 4.
Posed vs spontaneous smiles (cropped). The 4 panelists were also shown the series of spontaneous smiles along with their posed counterparts, with both images cropped to display only a standardized border beyond the vermilion of the lips. The panel members were asked to select the most diagnostically useful image. Once again, “diagnostically useful” was defined as the smile that appeared to be the most natural, the one that seemed to best represent the subject’s unsolicited smile. The layperson was told to select the smile that appeared most natural.
The raw data were standardized to account for magnification differences between the images measured. For the data sets comparing still images only, the measured length of the 1-in marker (25.4 mm) in the image was used to adjust for changes in magnification. The formula used in these cases is shown in Equation 1.
We were unable to use the 1-in marker as a standard measure for the video-derived images because the reproduced quality tended to blur the marker edges. Instead, the intercanthal distance was used for each subject because the data sets compared in this section were all taken at the same time, and thus there was no concern for change in head position or camera angulation. The formula used to standardize the data set that compared the video-derived images with the still images is shown in Equation 2.
The formula used to standardize the data set that compared the apices of the video-derived spontaneous smiles and the video-derived posed smiles is shown in Equation 3.
Statistical analysis
A power analysis was performed to determine the number of subjects required for this investigation. The maximum change in the width of a smile (commissure to commissure) considered by the principal investigator of this study (J.F.W.) to be diagnostically acceptable was measured on 4 subjects. At 2 times, each subject was asked to begin at his or her broadest smile and then to slowly reduce the smile until the examiner thought that the smile no longer had diagnostic quality. The change in width was found to average 4 mm. The full range of the smile was also measured; it averaged 13 mm. Using these estimates, we calculated that 22 subjects (11 men, 11 women) were required for the comparison between the different smiles obtained in this study, for a type I error of .05 and a 2-tailed test with 80% power.
All analyses performed on the objective measurements were done using the standardized data. The differences between days 1 and 2 were tested for significance using either a paired t test or the Wilcoxon signed rank test, depending on whether the assumptions of normality were met for the t test. The same approach was used to assess the significance of the following: (1) the differences between the still and video images, (2) the differences between the verbal and visual cues in the still photographs, and (3) the differences between the spontaneous and posed smiles taken from the video. Tests of significance were 2-tailed, with a type I error of .05. An intraclass correlation coefficient (ICC) for the repeated measurements was computed to determine reliability.
Results
A total of 22 subjects (11 women, 11 men) participated in this study. They were between the ages of 20 and 49, with average ages of 24.7 years for the men and 27.2 years for the women.
The average length of each subject’s videotaped session was about 57 seconds, with a range of 35 to 90 seconds. The videotape segments averaged 49 seconds for the women (range, 35-65 seconds) and 65 seconds for the men (range, 45 -90 seconds).
We considered the reproducibility of the posed smile. The results of the objective data are given in Table I ; for the most part, no statistically significant differences were found between the smile measurements taken on day 1 and day 2. The exception was the difference in commissure to commissure distance between the visually commanded smile on day 1 and the visually commanded smile on day 2. The mean difference in this instance was 1.51 mm, with a standard deviation of 2.93 mm and a range of 10.57 mm.
| Objective measurement (mm) | Verbal | Visual | ||||
|---|---|---|---|---|---|---|
| Mean difference ∗ | Range ∗ | Significance | Mean difference ∗ | Range ∗ | Significance | |
| Commissure to commissure | 0.9 | 8.9 | NS | 1.5 | 10.6 | S |
| Vermilion upper lip to vermilion lower lip | 0.4 | 9.0 | NS | 0.2 | 10.8 | NS |
| Superior lower lip to inferior upper lip | 0.5 | 9.1 | NS | 0.3 | 9.1 | NS |
| Upper incisal edge to inferior upper lip | 0.4 | 5.1 | NS | 0.1 | 4.2 | NS |
| Upper incisal edge to vermilion upper lip | 0.5 | 4.3 | NS | 0.3 | 5.6 | NS |
| Upper incisal edge to interpupillary line | 0.6 | 6.4 | NS | 0.1 | 5.8 | NS |
| Intercanthal distance | 0.1 | 3.8 | NS | 0.2 | 3.2 | NS |
No statistically significant differences were found when the verbally directed smiles of day 1 were compared with the visually directed smiles of day 1 ( Table II ). The only statistically significant difference in measurement was found between the intercanthal distances recorded on the verbally directed smiles on day 2 and the visually commanded smiles on day 2. The mean difference was 0.30 mm with a standard deviation of 0.49 mm and a range of 1.73 mm.
| Objective measurement (mm) | Day 1 | Day 2 | ||||
|---|---|---|---|---|---|---|
| Mean difference ∗ | Range ∗ | Significance | Mean difference ∗ | Range ∗ | Significance | |
| Commissure to commissure | 0.5 | 11.6 | NS | 1.0 | 14.2 | NS |
| Vermilion upper lip to vermilion lower lip | 1.0 | 3.2 | NS | 0.4 | 13.6 | NS |
| Superior lower lip to inferior upper lip | 1.2 | 13.4 | NS | 0.4 | 11.8 | NS |
| Upper incisal edge to inferior upper lip | 0.4 | 6.2 | NS | 0.4 | 7.6 | NS |
| Upper incisal edge to vermilion upper lip | 0.1 | 6.3 | NS | 0.3 | 7.7 | NS |
| Upper incisal edge to interpupillary line | 0.1 | 1.8 | NS | 0.2 | 3.6 | NS |
| Intercanthal distance | 0.1 | 1.8 | NS | 0.3 | 1.7 | S |
Stay updated, free dental videos. Join our Telegram channel
VIDEdental - Online dental courses


