Introduction
The decision to extract teeth for orthodontic treatment is important and difficult because it tends to be based on the practitioner’s experiences. The purposes of this study were to construct an artificial intelligence expert system for the diagnosis of extractions using neural network machine learning and to evaluate the performance of this model.
Methods
The subjects included 156 patients. Input data consisted of 12 cephalometric variables and an additional 6 indexes. Output data consisted of 3 bits to divide the extraction patterns. Four neural network machine learning models for the diagnosis of extractions were constructed using a back-propagation algorithm and were evaluated.
Results
The success rates of the models were 93% for the diagnosis of extraction vs nonextraction and 84% for the detailed diagnosis of the extraction patterns.
Conclusions
This study suggests that artificial intelligence expert systems with neural network machine learning could be useful in orthodontics. Improved performance was achieved by components such as proper selection of the input data, appropriate organization of the modeling, and preferable generalization.
Highlights
- •
The diagnosis of extractions is important in orthodontic treatment planning.
- •
Machine learning has been used for many decision-making processes.
- •
Artificial intelligence models made with machine learning did well in diagnosis of extractions.
- •
Neural network machine learning could be useful in various areas of orthodontics.
The most important part of orthodontic treatment is to determine the treatment plan. An important part of treatment planning is the decision about extractions and the teeth to be extracted, because extractions are irreversible. Therefore, a prudent decision about extractions is required. A wrong decision could result in many problems during the orthodontic treatment. Undesirable results could be obtained, or in the worst-case scenario, the treatment might not be finished. Problems could include failure of anchorage control, abnormal inclination of the anterior teeth, unfavorable profile, improper occlusion, inadequate overjet and overbite, and difficulties in the closure of extraction spaces. Generally, most orthodontists make a decision with data from the clinical evaluations, photographs, dental models, and radiographs based on their experience and knowledge. Since there is no formula for the treatment plan, the decision depends on the practitioner’s heuristics in many cases. This often causes intraclinician and interclinician variability in the treatment planning process. In addition, different records used for the diagnosis can cause differences in the treatment plan. Moreover, differences in treatment planning can occur between experienced and less-experienced practitioners. In particular, differences in extraction decisions could be critical. While allowing inexperienced practitioners to learn from the decisions of experienced practitioners would be helpful, decisions cannot be standardized with these combinations of measurements. Thus, another approach is needed.
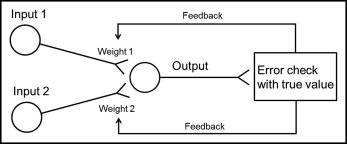
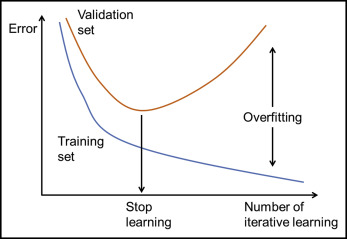
Recently, there have been many studies about artificial intelligence and bioinformatics. One approach is machine learning using a neural network system. This emulates human learning in a situation that cannot be formulized or standardized. The human neural system consists of neurons that are linked at the synapse to send information. By repeated learning, each synapse linkage can be reinforced or weakened. In machine learning with the neural network, neurons link the input to the output, and each neuron is linked at the synapse. In each synapse, information of the input neurons is collected by a weighting technique. Weighted values are adjusted through iterative learning ( Fig 1 ). Excessive iterative learning can elevate goodness-of-fit of the training set. However, errors of the test set can also be increased; this is called overfitting. To avoid this, a validation set is introduced to stop learning and to make a generalized model ( Fig 2 ). The generalized decision-making model can be formed through these procedures.
The aim of this study was to make an artificial intelligence decision-making model for the diagnosis of extractions using neural network machine learning. In addition, we wanted to evaluate the validity and accuracy of this model.
Material and methods
The subjects consisted of 156 patients who had visited Seoul National University Dental Hospital in Seoul, South Korea, for an orthodontic consultation. Exclusion criteria were persons with unerupted permanent teeth or missing teeth (except for third molars), malformed teeth, previous orthodontic treatment history, maxillofacial deformities, and orthognathic surgery. Inclusion criteria were persons included in 5 treatment plan groups: nonextraction, maxillary and mandibular first premolar extractions (Ext_type_44-44), maxillary and mandibular second premolar extractions (Ext_type_55-55), maxillary first premolar and mandibular second premolar extractions (Ext_type_44-55), and maxillary first premolar extractions only (Ext_type_44-00) ( Table I ). For all subjects, the treatment plans were determined by 1 orthodontic specialist (T-W.K.), who had more than 10 years of experience.
| Variable | n | Mean age (y) | SD |
|---|---|---|---|
| Sex | |||
| Female | 94 | 25 | 7 |
| Male | 62 | 23 | 6 |
| Type of extractions | |||
| No extractions | 62 | ||
| Ext_type_44-44 | 20 | ||
| Ext_type_44-55 | 36 | ||
| Ext_type_55-55 | 25 | ||
| Ext_type_44-00 | 13 | ||
| Type of learning | |||
| Learning set | 96 | ||
| Test set | 60 | ||
| Total | 156 | ||
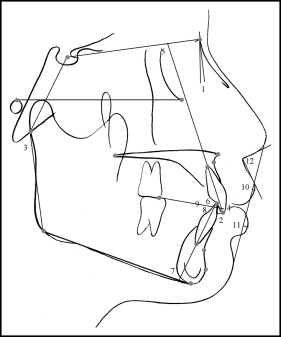
Lateral cephalograms were collected as orthodontic records for all subjects. All tracings were made by 1 investigator (S-K.J.) and repeated twice at intervals of 2 weeks to analyze measurement errors. The reference points were digitized with the V-ceph program (version 5.3; Osstem, Seoul, Korea). Twenty-six landmarks and 12 measurements were chosen ( Fig 3 ).
From this sample, 96 persons were assigned to the learning set, and 60 persons were assigned to the test set ( Table I ). The test set was used only for evaluation of the models. Two-thirds of the learning set was assigned to the training set and one-third of the learning set was assigned to the validation set. To find the optimal model, sliding window validation was performed. This is the validation technique to choose a validation set through the window moving sideways from the serial data. To prevent overfitting, iterative learning was stopped at the minimum error point of the validation set. Next, through evaluation of the test set, the adequacy and accuracy were evaluated, and the best-fit model was chosen.
A 2-layer neural network including 1 hidden layer was selected for the machine learning. There were 4 hidden nodes in the hidden layer. Hidden nodes play the role of interneurons in the artificial neural network system, and learning is performed through their weighted-values adjustment. Twelve measurements were selected for the input data: ANB angle, overjet, Björk sum, overbite, maxillary central incisor to SN angle, maxillary central incisor to occlusal plane angle, IMPA, mandibular central incisor to occlusal plane angle, interincisal angle, upper lip to E-line, lower lip to E-line, and nasolabial angle. These had clinical relevance such as anteroposterior relationships, vertical relationships, tooth inclinations, and soft tissue characteristics. In addition, 6 indexes—maxillary arch length discrepancy index, mandibular arch length discrepancy index, molar key index, large overjet index, protrusion index, and chief complaint index for protrusion—were included in the input data ( Table II ). The input data consisted of 18 elements in this manner. Maximum-minimum normalization was chosen for normalization of the input data in the range of 0 to 1. The learning rate was 0.9, and the sigmoid function was chosen as the activation function. The language R program ( http://www.r-project.org/ ) was used for coding to construct machine learning models. A back-propagation algorithm was applied to adjust the weighted values.
| Index | Weighting | Criterion (mm) |
|---|---|---|
| Arch length discrepancy | ||
| Spacing | 0 | ALD > 0 |
| Normal | 0.25 | −1 < ALD ≤ 0 |
| Mild crowding | 0.5 | −3 < ALD ≤ −1 |
| Moderate crowding | 0.75 | −5 < ALD ≤ −3 |
| Severe crowding | 1 | ALD ≤ −5 |
| Molar key | ||
| Class III key | 0 | |
| Super Class I key | 0.25 | |
| Class I key | 0.5 | |
| End-on key | 0.75 | |
| Class II key | 1 | |
| Large overjet | ||
| Not severe | 0 | Overjet ≤ 5 |
| Severe | 1 | Overjet > 5 |
| Protrusion | ||
| Concave profile | 0 | |
| Normal profile | 0.25 | |
| Mild protrusion | 0.5 | |
| Moderate protrusion | 0.75 | |
| Severe protrusion | 1 | |
| Chief complaint for protrusion | ||
| No protrusion in chief complaint | 0 | |
| Protrusion in chief complaint | 1 | |
Stay updated, free dental videos. Join our Telegram channel
VIDEdental - Online dental courses


