Introduction
Numerous studies of smile esthetics have used still photos. Photos, however, do not capture the dynamics of a smile, an element that can contribute to overall smile esthetics. In this study, we assessed the esthetics of dynamic smiles.
Methods
Four facially balanced female dental students were trained to produce 8 distinct smiles using the facial action coding system. Videos of the models’ whole faces were presented to 2 panels of raters: dental students and nondental undergraduate students. Smile attractiveness was rated using a Web-based survey.
Results
The smile that used 4 labial muscles was rated significantly better than the smile involving only the risorius muscle ( P <0.05). The orbicularis oculi improved smile attractiveness ( P <0.04), especially among smiles rated less favorably ( P <0.05). Visibility of the models’ eyes, however, did not influence the ratings ( P >0.05), perhaps because orbicularis oculi activation altered activations in other muscles in such a way that smile attractiveness was increased in the lower face.
Conclusions
Smile esthetics increased with increased recruitment of muscles involved in smile production. The results were robust across the models, suggesting that objective rating methods of smile-dynamic esthetics could become an important clinical tool.
Smiles play a critical role in esthetics and social behavior. With the reemergence of the esthetic paradigm in patient-centered care, smile enhancement has become increasingly important. However, a consensus on the criteria for smile esthetics does not yet exist. In this study, we quantified the esthetics of smiles and tested the reliability and repeatability of these measures.
Most investigations of smile esthetics did not examine the facial movements involved in smiling. The results were based on still images cropped to show only the subject’s lips and dentition. A smile, however, consists of dynamic movements that cannot be captured by still images. For instance, Tarantili et al identified 3 phases in the motion of a spontaneous smile: an initial attack phase, a sustaining phase, and a fade-out phase. Smiles transition between these phases through time; therefore, it is impossible to render a complete smile in a single photograph.
Studies of smile dynamics suggest that facial movements are critical in esthetic assessments of a smile. Rubenstein showed low correspondence between the attractiveness ratings of a face presented in the static vs the dynamic format. Static images probably relay structural facial information, whereas the dynamic format introduces nonstructural features such as emotions. These observations suggest a critical need to develop objective methods to quantify and assess dynamic smile esthetics. The facial action coding system is a standardized method of describing facial muscular activity during facial expressions. The system identifies 46 distinct facial movements described as action units. Most smiles involve contraction of the zygomaticus major muscle, action unit 12, and constriction of the eyes through contraction of the orbicularis oculi, action unit 6. Action unit 6, also called “Duchenne’s marker,” has been associated with spontaneous smiles or true enjoyment. Subjects asked to use action unit 6 during smiling report feeling more positive emotions, and they display concomitant changes in central nervous system activity.
The facial action coding system relies on subjective interpretations by observers. Ekman and Friesen attempted to overcome this subjectivity by calibrating and certifying facial action coding system observers. This calibration improved intrarater reliability; however, interrater reliability remained less than ideal.
Gracely et al developed a box scale to differentiate between sensory and affective components of pain. The scale has demonstrated high correlations between sessions, groups, and experiments, and it has high internal and external validity. Because of its power and validity as a rating method, the scale was modified to provide esthetic ratings in our study.
The aims of this study were to examine (1) whether specific attributes of dynamic smiles were involved in esthetic ratings, (2) the role of the eyes in esthetic measurements, and (3) the agreement between dental professionals and laypeople on perceptions of dynamic smile esthetics.
Material and methods
The study was approved by the University of Michigan’s institutional review board. Smile models were recruited from the predoctoral dental classes at the University of Michigan School of Dentistry. Inclusion criteria were (1) women, ages 20 to 30 years; (2) good facial and skeletal balance based on extraoral examinations; (3) good general health; and (4) good dental health with functional dentitions. The models were within 15% of the ideal body mass index for their age, and they had no history of organic disease, congenital disease, orofacial pain, dysfunction, arthritis, joint noises or restrictions, and medications known to interfere with affective or motor parameters. The models were required to follow the instructions to learn to perform specific smiles on command. Only female models were selected for this initial study to simplify interpretation of the results by controlling for sex effects.
The exclusion criteria were based on the study of Kokich et al of altered dental esthetics: maxillary incisor angulation ≥2 mm from ideal, maxillary midline ≥4 mm from the facial midline, open gingival embrasure between the maxillary central incisors ≥2 mm (space between the tip of the interdental papilla and the interproximal contact point), maxillary incisal plane deviation ≥1 mm, and gingiva-to-lip distance ≥2 mm at the maximum smile. The final 4 models were selected by an orthodontic expert (A.L.) from the original sample of 8 candidates, all of whom met the inclusion and exclusion criteria described above.
The 4 models were trained to produce 8 different smiles ( Fig 1 ). The study smiles were carefully constructed using the facial action coding system to control for variations in smiles. The activity in action units was monitored visually to reduce unwanted variations in smile dynamics.
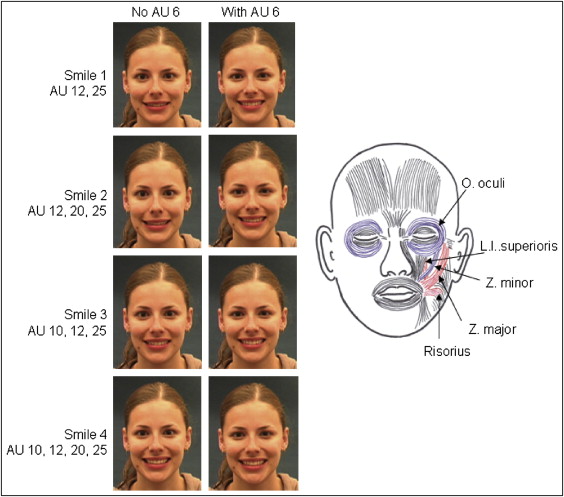
The action units used included (1) action unit 6, “cheek raise,” contraction of the orbicularis oculi; (2) action unit 10, “upper lip raiser,” contraction of the zygomaticus minor and levator labii superioris; (3) action unit 12, “lip corner puller,” contraction of the zygomaticus major; (4) action unit 20, “lip stretch,” contraction of the risorius; and (5) action unit 25, “lips part,” used by the facial action coding system to indicate parting of the lips, thus showing the dentition ( Fig 1 ).
All smiles were controlled for absence of nostril flare, chin and forehead muscle movements, eye movements, movements at the glabella, blinking, and unwanted muscle movements involving the lips.
The models were trained by 1 investigator (A.L.) to produce all 8 smiles naturally from the rest position. The models practiced as many times as necessary to achieve the desired movements, timing, and spontaneity. The smiles were videotaped with a camcorder aligned with the model’s midsagittal plane to provide a full frontal view of the face. The camera was located near the level of the subject’s Frankfort horizontal plane and 2 m from the subject’s face.
Upon command, the subjects produced each smile starting from the neutral position, held the maximum position for 2 seconds, and then returned to the neutral position. Hence, the total smile episode, from neutral back to neutral, lasted about 3 seconds, which is the duration of many human motor events and their perceptions. Training typically lasted 15 to 30 minutes for each model and involved having them watch themselves in a mirror while performing each smile on verbal commands. After training, 2 or 3 trials were necessary to obtain a video clip in which a satisfactory smile was performed. The videos then were screened by the same investigator to identify the best clip to represent each smile for each model.
Videos were edited in i-Movie (Apple Inc, Cupertino, Calif) and converted into individual 3-second clips in MPEG 4 format. Each clip was 7 × 6.2 cm (2.8 × 2.44 in) on the computer monitor and showed the entire head and neck region of the model plus the top of the shoulders. The clips were duplicated, and the copy was edited to include a rectangular block (7 × 1.9 cm, or 2.8 × 0.75 in) that covered the model’s eyes and nose ( Figs 2 and 3 ). This approach resulted in 16 video clips (8 smiles with and without the rectangular block) for each model.

Two rater panels were recruited from the University of Michigan and signed informed consent forms to participate. The dental panel consisted of dental students in their first to fourth years. The lay panel consisted of students from the Department of Psychology research subject pool. Anyone over 18 years old was invited to participate. The dental panel consisted of 52 raters (31 women, 21 men), and the lay panel included 31 subjects (15 women, 16 men; Table I ).
| Panel | Sex (F:M) | Age (y) | Ethnicity (W:As:Af:H:I:U) | ||
|---|---|---|---|---|---|
| <21 | 21-25 | >25 | |||
| Dental | 31:21 | 0 | 42 | 10 | 32:14:5:0:1:0 |
| Lay | 15:16 | 25 | 6 | 0 | 25:2:0:2:0:2 |
| Total | 46:37 | 25 | 48 | 10 | 57:16:5:2:1:2 |
A Web-based survey was created containing 5 parts. Each part had detailed instructions and examples of the tasks to be completed. The raters were allowed to watch the smile videos as many times as needed to make their decisions. They were not allowed to skip responses or change their responses once answered.
In part 1, rater participant data, the raters’ demographic information including sex, age, ethnicity, occupation, and sexual orientation were collected. The participants also indicated whether they knew any of the models before this study. It was determined that the raters gave higher scores to models whom they knew than to those they did not know ( P <0.001). Therefore, data representing models whom raters knew were removed from analyses.
In part 2, overall facial attractiveness of the models, photographs of the 4 models were presented on 1 Web page. The pictures showed only the models’ heads, and all models were performing smile 4 in the photos. The participants were asked to rate each model’s overall facial attractiveness on a scale of 1 to 10, with 1 the least attractive and 10 the most attractive.
Based on the ratings in the preliminary pilot study, the attractiveness ratings of models C and H were similar to each other, whereas the ratings of models K and S were similar to each other. As a result, only one of models C and H and only one of models K and S were assigned randomly to each rater for parts 3 and 4 of the survey.
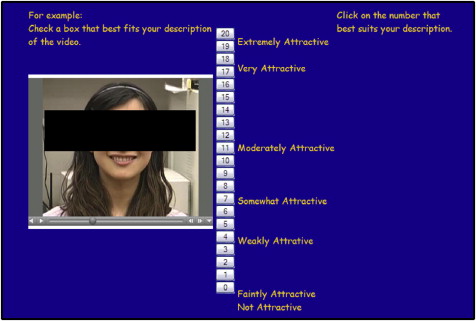
In part 3, box scale, all 32 videos (16 per model × 2 models) were presented to a rater 3 times in random order, requiring 96 total responses (3 × 32). The raters selected the number in the box scale corresponding to their impression of the attractiveness of each smile ( Fig 2 ).
In part 4, forced comparison, 2 videos were presented simultaneously, and the raters were forced to choose which of the 2 smiles was more esthetic ( Fig 3 ). The paired videos were selected randomly using the following rules: (1) the pair represented the same model; and (2) the pair differed from each other in only one of 3 ways—type of smile (smile 1, 2, 3, or 4), use of the eyes (action unit 6 used or not used), or blocking of the eyes (eyes blocked or eyes visible). This protocol resulted in 40 paired video presentations for each model: ie, 2 eye-use conditions times 2 eye-blocking conditions times 10 smile pairs—smiles 1 and 1, 1 and 2, 1 and 3, 1 and 4, 2 and 2, 2 and 3, 2 and 4, 3 and 3, 3 and 4, and 4 and 4.
To control for spatial order effects, each of the 40 video pairs was presented twice using an algorithm that changed the left-to-right ordering randomly on the screen. This resulted in the raters viewing a total of 80 (40 × 2) pairs of smile videos for each model. Since each rater viewed the smiles from 2 models, 160 total presentations were rated.
In part 5, overall facial attractiveness of models, at the end of the survey, the raters were asked once again to rate each model’s overall facial attractiveness on a scale of 1 to 10. The presentation of this part was identical to part 2.
The raters took the survey at the walk-in computer center in the University of Michigan School of Dentistry with the Mozilla Firefox web-browser software (Mozilla Foundation, Mountain View, Calif) on personal computer desktops linked to a high-speed Internet cable.
Statistical analysis
Descriptive statistics were calculated for the raters including sex, age, ethnicity, and sexual orientation. Parametric tests were used to analyze the box-scale data (part 3, above). The mean box score for each smile was plotted to identify rating trends that might have existed across the 3 presentations of each video. Data from the second video presentation were chosen for analysis using a univariate analysis of variance (SPSS version 17.0.1; SPSS, Chicago, Ill) to study effects from smile type, use of action unit 6, blocking of eyes, rater panel, rater age, and rater sex.
Data from the forced comparison (part 4) were analyzed using multinomial logistic regression. Logistic regression is used to predict the probability of the occurrence of an event based on a set of dependent and independent variables.
For this study, 3 forced-comparison analyses were performed using multinomial logistic regression: (1) comparing the 4 smile types while holding “use of action unit 6” and “blocking of eyes” constant; (2) comparing “use of action unit 6” while holding smile type and “blocking of eyes” constant; and (3) comparing “blocking of eyes” while holding smile type and “use of action unit 6” constant.
As an example, to compare smile types while holding “use of action unit 6” and “blocking of eyes” constant, we first determined for each rater the number of times each smile type was selected in the forced comparison with every combination of eye use and eye block. The frequencies of the 4 smile types then were modeled with multinomial logistic regression as a function of the participant’s sex, age, panel, smile, use of action unit 6, and blocking of eyes. Because each rater evaluated a given smile many times during the survey, all P values were computed using bootstrap methods to adjust for this repeated-measure dependency.
Stay updated, free dental videos. Join our Telegram channel
VIDEdental - Online dental courses


