Peptides and proteins
Publisher Summary
This chapter focuses on peptides and proteins. From a biological point of view, the most important reaction that the amino acids undergo is the condensation and formation of peptide bonds. This reaction is responsible for a vast spectrum of compounds containing anything from two to many hundreds of amino acid residues. The smaller members of the group containing less than 10–20 residues are classed as oligopeptides, while above this, they are known as oligopeptides. It is customary, however, to refer to polypeptides that have a molecular weight of more than 10,000 as proteins and those with lower values simply as peptides. This distinction is arbitrary but convenient. The average molecular weight of the amino acid residues present in polypeptides is rather less than 110 so that a molecular weight of 10,000 is roughly equivalent to 100 residues. Although the mammalian peptides normally contain only those amino acids that are found in proteins linked by normal peptide bonds, some of the peptides produced by microorganisms show unusual features, such as the presence of ornithine and of D-amino acids. Peptides are widely distributed in nature and show a great range of biological activities. Most tissues contain them and more than 30 have been found in the mammalian nervous system. Proteins comprise more than half the solid matter of the body. Proteins are macromolecules and have colloidal properties, but their molecules are not necessarily very large.
From the biological point of view the most important reaction which the amino acids undergo is condensation and the formation of peptide bonds (page 39). This reaction is responsible for a vast spectrum of compounds containing anything from two to many hundreds of amino acid residues. The smaller members of the group containing less than 10–20 residues are classed as oligopeptides while above this they are known as polypeptides. It is customary, however, to refer to polypeptides which have a molecular weight of more than 10000 as proteins and those with lower values simply as peptides. This distinction is arbitrary but convenient. The average molecular weight of the amino acid residues present in polypeptides is rather less than 110 (Table 4.1), so that a molecular weight of 10000 is roughly equivalent to 100 residues.
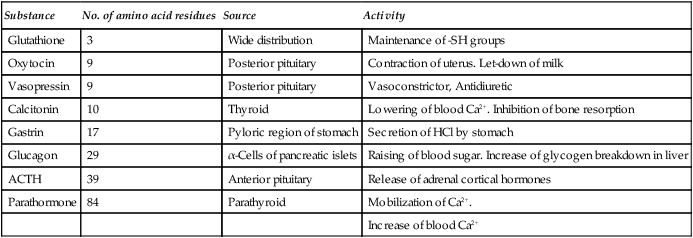
Table 5.1
Some biologically active peptides of animal origin
| Substance | No. of amino acid residues | Source | Activity |
| Glutathione | 3 | Wide distribution | Maintenance of -SH groups |
| Oxytocin | 9 | Posterior pituitary | Contraction of uterus. Let-down of milk |
| Vasopressin | 9 | Posterior pituitary | Vasoconstrictor, Antidiuretic |
| Calcitonin | 10 | Thyroid | Lowering of blood Ca2+. Inhibition of bone resorption |
| Gastrin | 17 | Pyloric region of stomach | Secretion of HCl by stomach |
| Glucagon | 29 | α-Cells of pancreatic islets | Raising of blood sugar. Increase of glycogen breakdown in liver |
| ACTH | 39 | Anterior pituitary | Release of adrenal cortical hormones |
| Parathormone | 84 | Parathyroid | Mobilization of Ca2+. |
| Increase of blood Ca2+ |
Peptides
Peptides are widely distributed in nature and show a great range of biological activities. Most tissues contain them and more than 30 have been found in the mammalian nervous system. They are also present in plants, fungi and bacteria and include some of the most biologically active compounds known. Some of the antibiotics, e.g. penicillin, gramicidin and chloramphenicol, are essentially peptide in character as are some extremely toxic substances, e.g. the fungal poisons amanitin and phalloidin. The botulinus, tetanus and black widow spider toxins are all polypeptide neurotoxins. A list of some of the best characterized peptides is given in Table 5.1. They include hormones, released from the hypothalamus, posterior pituitary, gut and pancreas and neuropeptides such as the opioids and tissue growth factors.
The mammalian peptides often occur in families which may be products of a single gene or of closely related multiple genes. Peptides are currently arousing considerable interest because neuropeptides are now thought to play a part not only in pain perception, in feeding and temperature control but also in memory and learning ability! More is said about the neuropeptides and tissue growth factors in Chapter 24.
Proteins
Proteins comprise more than half the solid matter of the body. They are responsible for virtually all the reactions which occur within the tissues as well as being of structural importance. Proteins are macromolecules and have colloidal properties but their molecules are not necessarily very large. Their molecular weights range from an arbitrary lower limit of 10000 to several million and from its DNA content it has been estimated that the human body contains some 100000 different types of protein. Proteins are, moreover, usually unique to the species from which they are derived so that human serum albumin is distinct from that of a duck, dog, hen or horse and, although similar in structure and function, they have slight differences in composition and are immunologically distinct. From this it can be seen that proteins must exist in almost infinite variety and some idea of the range of their functions may be obtained from Table 5.2. Nevertheless all proteins are derived from the same selection of 20 amino acids which are joined by peptide linkages into long unbranched polypeptide chains. Their main distinguishing characteristics lie in the precise selection of amino acids and the sequence or order in which they follow one another in the polypeptide chain which is genetically determined.
Table 5.2
Functional classification of proteins

1. between different parts of the same chain
2. between two or more chains which may be of the same or different types
3. between a polypeptide chain and a non-protein molecule or molecules. This latter type of interaction produces the so-called conjugated proteins, e.g. haemoglobin, the lipoproteins of cell membrances and the nucleoproteins of the chromosomes. The non-protein part of the molecule is known as the prosthetic group.
Proteins can be broadly divided into two categories – fibrous and globular.
Fibrous proteins
In the fibrous proteins a large number of molecules of the same type associate to form sheets or bundles. Association of the molecules occurs in the first instance as the result of the formation of weak non-covalent bonds but, subsequently, strong covalent bonds develop which convert the structure into a rigid insoluble aggregate usually of considerable strength. The structure of keratin is dealt with on page 401, fibrin on page 386 and collagen and elastin in Chapter 27.
Globular proteins
There are an enormous number of soluble proteins each of which fulfils a specific function or functions. They are usually more or less globular in shape and have highly characteristic conformations which are designed to bring particular reactive chemical groups together or to force them apart. To do this the molecules must be folded in a complex manner in order to produce a specific shape and charge pattern. The larger proteins often consist of two or more separate chains which may or may not be identical. Such proteins are said to be oligomeric and their constituent chains are known as subunits or monomers. Oligomeric proteins usually have more complex functions than single chain proteins. They are often able to react appropriately to physiological changes and hence play an important part in the control of metabolism (Chapter 23). The folded shapes of the globular proteins are inherently flexible and are able to undergo subtle changes which relate to their biological function. The normal biologically active form of such proteins is known as the native form and when major changes in its three-dimensional characteristics are induced by some external agent and cause a marked reduction in its biological activity, the protein is said to be denatured (page 63).
The ionization of proteins
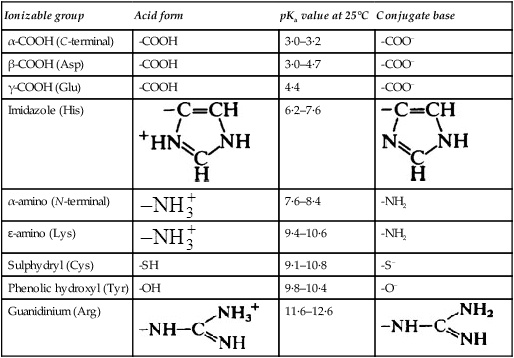
Nearly all the ionizable groups of proteins are contributed by the side chain groups of amino acid residues because all but the terminal α-amino and α-carboxyl groups are involved in peptide linkages which do not ionize. The properties of the main ionizable groups in proteins are summarized in Table 5.3.
Table 5.3
The ionizable groups of proteins
| Ionizable group | Acid form | pKa value at 25°C | Conjugate base |
| α-COOH (C-terminal) | -COOH | 3·0–3·2 | -COO− |
| β-COOH (Asp) | -COOH | 3·0–4·7 | -COO− |
| γ-COOH (Glu) | -COOH | 4·4 | -COO− |
| Imidazole (His) | 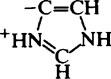 |
6·2–7·6 | 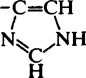 |
| α-amino (N-terminal) |  |
7·6–8·4 | -NH2 |
| ɛ-amino (Lys) |  |
9·4–10·6 | -NH2 |
| Sulphydryl (Cys) | -SH | 9·1–10·8 | -S− |
| Phenolic hydroxyl (Tyr) | -OH | 9·8–10·4 | -O− |
| Guanidinium (Arg) | 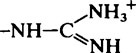 |
11·6–12·6 | 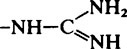 |
Proteins, like amino acids, have an isoelectric point at which they are ‘self-neutralized’ and have zero net charge. The isoelectric point is largely determined by the ratio of the free acidic (Asp and Glu) to basic (Lys and Arg) amino acid residues. The majority of proteins contain a preponderance of the acidic amino acids, that is Glu + Asp, so that their isoelectric point (pI) is less than 7·0, and they are negatively charged at neutral pH. On the other hand, basic proteins such as the histones, which have a marked preponderance of lysine and arginine, are positively charged at neutral pH. Proteins with different isoelectric points will interact, and a basic protein will tend to form a precipitate with an acidic one. Insulin protaminate formed by combination of insulin (pI 5) with protamine (pI 12) is relatively insoluble and is more slowly absorbed in the body; consequently it has a more prolonged action than ordinary insulin. In the cell nucleus, basic histones are bound to the nucleic acids and may function as regulators of gene activity (Chapter 21).
Protein purification and identification
1. With a few exceptions, such as haemoglobin, myosin and collagen, individual proteins are present to an extent of less than 0.5% of the starting material.
2. Proteins rarely, if ever, occur singly and, since they differ essentially only in the proportions and sequence of their constituent amino acids, their reactions are very similar so that their separation requires highly selective methods.
3. Owing to the reactivity and instability of most proteins many of the chemical and physical agents which might otherwise be employed cause their denaturation (page 63). Proteins are, for example, sensitive not only to heat and extremes of pH but also to the presence of organic solvents, detergents, heavy metals and many other substances.
The size and shape of protein molecules
The molecular weight of a single molecular species is, of course, independent of the method used for its determination. However, owing to the tendency of protein molecules to associate and form aggregates, e.g. gels and fibres, or complexes with other cell constituents such as lipids and nucleic acids, one of the problems of the protein chemist is to decide whether the entities under any given conditions represent a single molecular species or a molecular aggregate. For example, it has been established that the molecule of haemoglobin is made up of four separate polypeptide chains that may only be separated under conditions which are outside the physiological range. The individual chains are consequently regarded as subunits of the haemoglobin molecule. It is now recognized that many large proteins are built up of smaller subunits (Table 5.4). The subunits are held together by non-covalent bonds which are weak enough to be broken by reagents, such as urea, that are unable to break covalent bonds. The construction of large units from a number of smaller ones is a sound building principle which increases the flexibility of the resulting structure and reduces the likelihood of errors. Thus if any single unit is defective either it has little effect on the structure as a whole or it may be rejected in favour of a normal one.
Table 5.4
Molecular weights and subunit constitution of various proteins
| Protein | Molecular weight | Number of subunits |
| Ribonuclease | 12600 | 1 |
| Lysozyme (egg white) | 13900 | 1 |
| Myoglobin | 16900 | 1 |
| Malate dehydrogenase | 66300 | 2 |
| Glycerol-1-phosphate dehydrogenase | 78000 | 2 |
| Creatine kinase | 80000 | 2 |
| Enolase | 82000 | 2 |
| α-Amylase | 97600 | 2 |
| Haemoglobin | 64500 | 4 |
| Hexokinase | 102000 | 4 |
| Lactate dehydrogenase | 150000 | 4 |
| Fumarase | 194000 | 4 |
| Catalase | 232000 | 4 |
| Pyruvate kinase | 237000 | 4 |
| Glucose-6-phosphate dehydrogenase | 240000 | 6 |
| Mitochondrial ATPase | 284000 | 10 |
| Phosphorylase a | 370000 | 4 |
| Glutamine synthetase |
Stay updated, free dental videos. Join our Telegram channel
VIDEdental - Online dental courses


